Our preliminary work has been accepted as an oral presentation at CVPR 2025.
You can find more details at the following link.
Abstract
We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-Consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior—mirroring the causal structure of language—into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways:
Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models: By representing images with Selftok tokens, we can train vision-language models (VLMs) using a purely discrete autoregressive architecture—like that in LLMs—without requiring additional modules or training objectives.
We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs.
Besides the AR property, Selftok is also a SOTA tokenizer that achieves both high-quality reconstruction and high compression bit rate. After representing the training images as Selftok tokens, as a pure AR model, our VLM achieves both SOTA visual comprehension and generation performances. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin.
Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM.
Introduction
Why Discrete?
Comparison of (a) pure discrete autoregressive model (dAR) and (b) hybrid model that combines dAR and continuous autoregressive model (cAR).
<BOS>/<BOV> indicates the start of a sentence/image.
wi/vi denotes the i-th language/visual token.
Both models predict the next token given all previous ones, e.g.,
[<BOS>,…,<v3>]→<v4>.
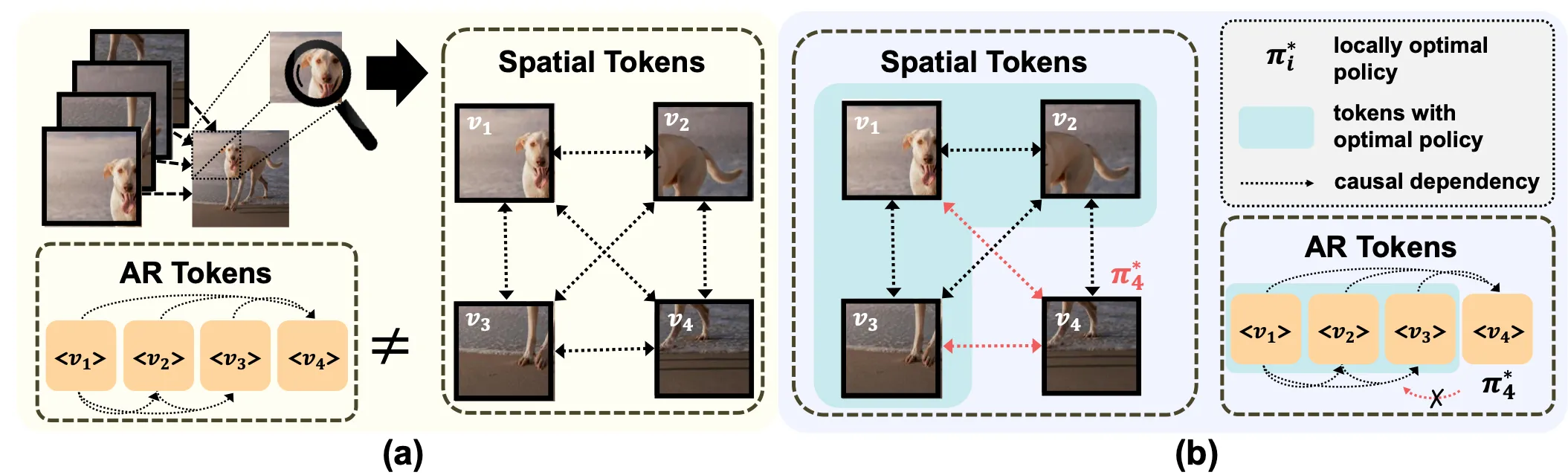
Why Not Spatial?
(a) As an image can be viewed as the effect of spatial pixels (or patches), observing any part of it introduces spurious dependencies among spatial tokens, making them non-AR.
(b) Due to the anti-causal links (red) for spatial tokens, learning the locally optimal policy π4∗ for a later token (e.g., v4) can propagate backward and interfere with earlier tokens that were already optimized (e.g., v1,v2,v3).
In contrast, AR tokens without such links do not have this issue.
Progressive Reconstruction & Interpolation
Progressive reconstruction (left to right): Reconstructions by progressively masking out a shorter sequence of tokens before inputting to the decoder. Here, we visualize the tokens in reverse order because we did not train the decoder with the normal sequence.
Interpolation (left to right): Reconstructions by gradually replacing tokens of the left image with those of the right one.
All methods except Selftok exhibit strong spatial characteristics i.e., tokens⇔patches.
Selftok: Self-Consistency Tokenizer
Architecture
Selftok architecture diagram. +POS: adding positional embeddings;
LN: layernorm; AdaLN: token-aware adaptive layernorm,
which differentiates token embeddings; MSE: the mean squared error
for the reconstruction objective; DM: pre-trained diffusion model.
Main Results
Tokenizer
Type
#Token
#Code
rFID↓
PSNR↑
SSIM↑
LPIPS↓
LlamaGen
2D
MaskBiT†
2D
-
Cosmos
2D
VQGAN-LC†
2D
OpenMagViT-V2
2D
ViT-VQGAN†
2D
-
-
-
LlamaGen
2D
Cosmos
2D
VAR
2D
TiTok-L-32
1D
TiTok-B-64
1D
TiTok-S-128
1D
FlexTok
1D
FlowMo-Lo†
1D
FlowMo-Hi†
1D
Selftok (Ours)
1D
Selftok (Ours)
1D
Reconstruction performance of different tokenizers on - resolution ImageNet 50k validation set.
† Results from the original paper.
Evaluation of text-to-image generation ability on GenEval benchmark.
Janus-Pro-7B† represents the result of our evaluation.
Janus-Pro-7B-Zero represents a model that has undergone the same visual RL process as Selftok-Pre-Zero and Selftok-Zero. † represents the result of our evaluation. ‡ GPT-4o results are from OpenAI’s technical report.
Type
Method
Single Obj.
Two Obj.
Counting
Colors
Position
Color Attr.
Overall
Diffusion Only
PixArt-α
SDXL
FLUX.1-dev
DALL-E 3
SD3-Medium
CogView4-6B
HiDream-I1
Hybrid Model
SEED-X
Transfusion
D-DiT
Show-o
GPT-4o‡
Pure dAR
Emu3-Gen>
TokenFlow-XL
ILLUME+
Infinity
Janus-Pro-7B
Janus-Pro-7B†
Janus-Pro-7B-Zero
Selftok-Pre
Sefltok-Pre-Zero
Selftok-SFT
Selftok-Zero
Performances on DPG-Bench. The methods in this table are all generation-specific models except Show-o, Janus-Pro, and Selftok. † represents the result of our evaluation.
Type
Method
Global
Entity
Attribute
Relation
Other
Overall
Diffusion Only
PixArt-α
SDXL
DALL-E 3
SD3-Medium
FLUX.1-dev
CogView4-6B
HiDream-I1
Hybrid Model
Show-o
Pure dAR
Emu3-Gen
Janus
Infinity
Janus-Pro-7B
Janus-Pro-7B†
Janus-Pro-7B-Zero
Selftok-Pre
Selftok-SFT
Selftok-Zero
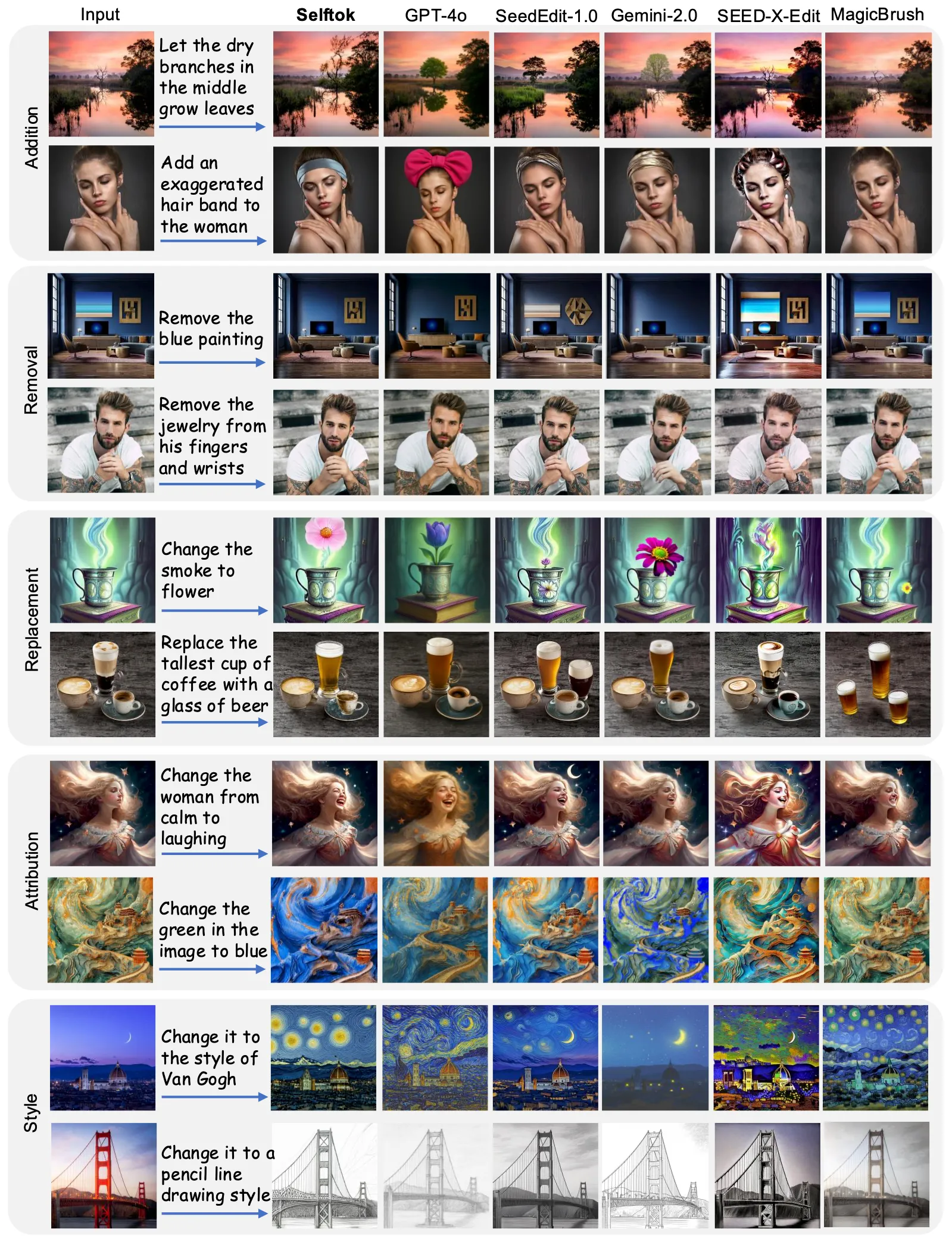
Examples
Text-to-Image Generation
Text-to-Image generation results by Selftok using the text prompts of DPG-Bench